Testing if "bash is all you need"
There's a growing conviction in the AI community that filesystems and bash are the optimal abstraction for AI agents. The logic makes sense: LLMs have been extensively trained on code, terminals, and file navigation, so you should be able to give your agent a shell and let it work.

Even non-coding agents may benefit from this approach. Vercel's recent post on building agents with filesystems and bash showed this by mapping sales calls, support tickets, and other structured data onto the filesystem. The agent greps for relevant sections, pulls what it needs, and builds context on demand.
But there's an alternative view worth testing. Filesystems may be the right abstraction for exploring and retrieving context, but what about querying structured data? We built an eval harness to find out.
Setting up the eval
We tasked agents with querying a dataset of GitHub issues and PRs. This type of semi-structured data mirrors real-world use cases like customer support tickets or sales call transcripts.
Questions ranged from simple:
How many open issues mention 'security'?
to complex:
Find issues where someone reported a bug and later someone submitted a PR claiming to fix it.
Three agent approaches competed:
- SQL agent: Direct database queries against a SQLite database containing the same data
- Bash agent: Using
just-bashto navigate and query JSON files on the filesystem - Filesystem agent: Basic file tools (search, read) without full shell access
Each agent received the same questions and was scored on accuracy.
Initial results
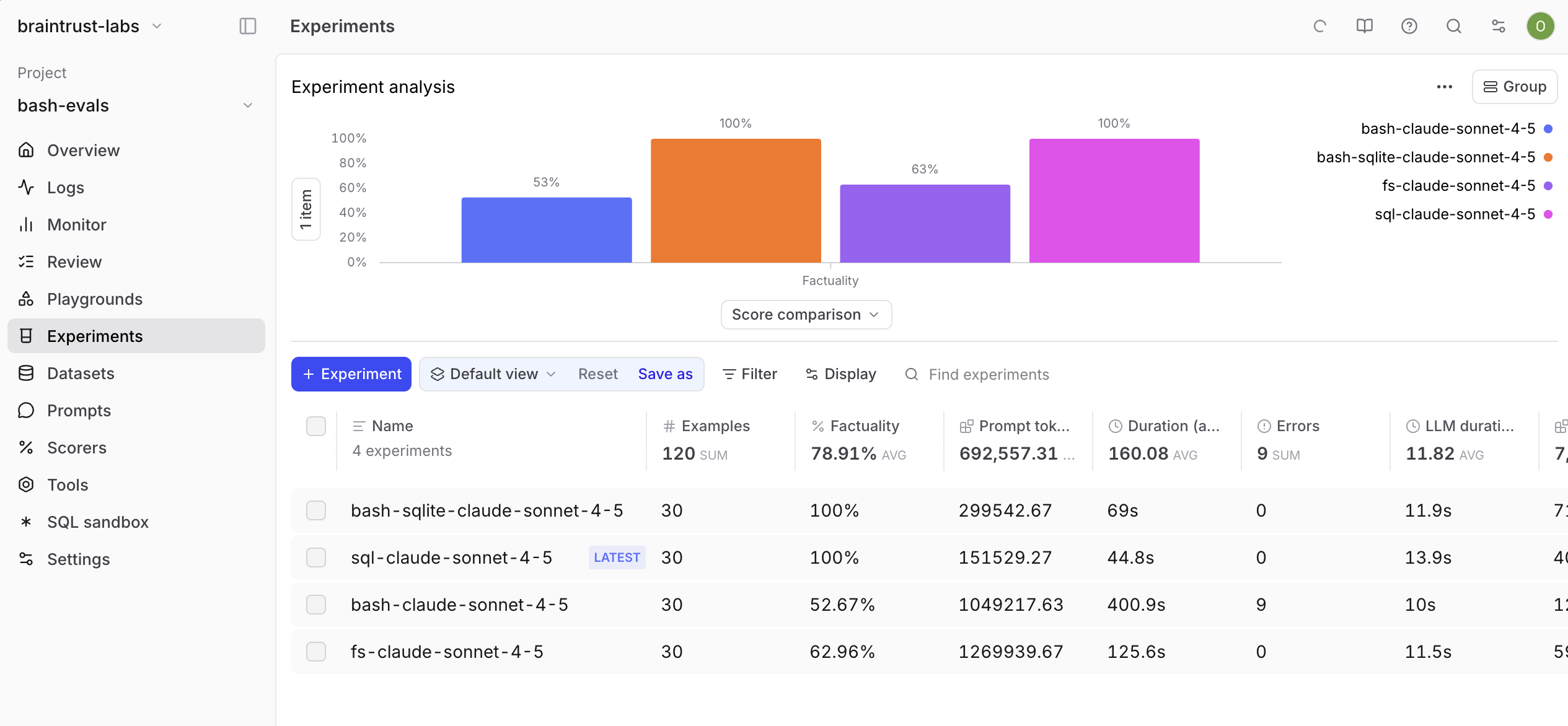
| Agent | Accuracy | Avg Tokens | Cost | Duration |
|---|---|---|---|---|
| SQL | 100% | 155,531 | $0.51 | 45s |
| Bash | 52.7% | 1,062,031 | $3.34 | 401s |
| Filesystem | 63.0% | 1,275,871 | $3.89 | 126s |
SQL dominated. It hit 100% accuracy while bash achieved just 53%. Bash also used 7x more tokens and cost 6.5x more, while taking 9x longer to run. Even basic filesystem tools (search, read) outperformed full bash access, hitting 63% accuracy.
You can explore the SQL experiment, bash experiment, and filesystem experiment results directly.
One surprising finding was that the bash agent generated highly sophisticated shell commands, chaining find, grep, jq, awk, and xargs in ways that rarely appear in typical agent workflows. The model clearly has deep knowledge of shell scripting, but that knowledge didn't translate to better task performance.
Debugging the results
The eval revealed real issues in the bash approach:
Performance bottlenecks: Commands that should run in milliseconds were timing out at 10 seconds. Profiling showed that stat() calls on 68k files were the culprits. These got optimized in just-bash.
Missing schema context: The bash agent didn't know the structure of the JSON files it was querying. Adding schema information and example commands to the system prompt helped, but not enough to close the gap.
Eval scoring issues: Hand-checking failed cases revealed several questions where the "expected" answer was actually wrong, or where the agent found additional valid results that the scorer penalized. Five questions got corrected:
- "Which repositories have the most unique issue reporters" was ambiguous between org-level and repo-level grouping
- Several questions had expected outputs that didn't match the actual dataset
- The bash agent sometimes found more valid results than the reference answers included
The Vercel team submitted a PR with the corrections.
After fixes to both just-bash and the eval itself, the gap narrowed significantly. We re-ran the experiments with the latest fixes.
The hybrid approach
Then we tried a different idea. Instead of choosing one abstraction, give the agent both:
- Let it use bash to explore and manipulate files
- Also provide access to a SQLite database when that's the right tool
The hybrid agent developed an interesting behavior: it would run SQL queries, then verify results by grepping through the filesystem. This double-checking is why the hybrid approach consistently hits 100% accuracy, while pure SQL occasionally gets things wrong.
You can explore the hybrid experiment results directly.
The tradeoff is cost: the hybrid approach uses roughly 2x as many tokens as pure SQL, since it reasons about tool choice and verifies its work.
What we actually learned
After all the fixes to just-bash, the eval dataset, and data loading issues, bash-sqlite emerged as the most reliable approach. The "winner" wasn't raw accuracy on a single run, but consistent accuracy through self-verification.
Over 200 messages and hundreds of traces later, we had:
- Fixed performance bottlenecks in
just-bash - Corrected five ambiguous or wrong expected answers in the eval
- Found a data loading bug that caused off-by-one errors
- Watched agents develop sophisticated verification strategies
The bash agent's tendency to check its own work turned out to be valuable not for accuracy, but for surfacing problems that would have gone unnoticed with a pure SQL approach.
What this means for agent design
For structured data with clear schemas, SQL remains the most direct path. It's fast, well-understood, and uses fewer tokens.
For exploration and verification, bash provides flexibility that SQL can't match. Agents can inspect files, spot-check results, and catch edge cases through filesystem access.
But the bigger lesson is about evals themselves. The back-and-forth between Braintrust and the Vercel team, with detailed traces at every step, is what actually improved the tools and the benchmark. Without that visibility, we'd still be debating which abstraction "won" based on flawed data.
Run your own benchmarks
The eval harness is open source.
You can swap in your own:
- Dataset (customer tickets, sales calls, logs, whatever you're working with)
- Agent implementations
- Questions that matter to your use case