Arize AI alternatives: Top 5 Arize competitors compared (2026)
Braintrust wins for teams shipping production LLM applications. CI/CD-native evals, automatic tracing, collaborative experiments, and self-hosting options make it the most complete platform.
Runner-up alternatives:
- Langfuse - Open-source flexibility, but you build evals yourself
- Fiddler AI - Enterprise ML and LLM monitoring, but lacks CI/CD deployment blocking
- Galileo AI - Great if you need packaged evaluators and runtime guardrails ready out of the box
- Helicone - OpenAI cost tracking only
Choose Braintrust if automated evaluation in CI/CD and production observability with proactive insights matter. Pick others if you only need basic logging or have specific constraints (e.g., open-source, inline runtime guardrails, etc.).
Why teams look for Arize AI alternatives
Arize AI started as an ML model monitoring platform focused on traditional machine learning operations. The company built features for drift detection, model performance tracking, and tabular data monitoring, but these are tools designed for predictive ML models deployed years ago.
As LLM applications moved from prototypes to production, Arize expanded into generative AI through its Arize Phoenix open-source framework and later added LLM capabilities to its web application. Arize now offers LLM evaluation, prompt versioning through their Prompt Hub, and tracing for conversational applications.
However, teams building production LLM applications encounter specific workflow gaps:
- ML-first architecture. Arize's platform was built for traditional ML workflows. LLM evaluation, prompt management, and generative AI tracing were added later, creating a disconnected experience between classical model monitoring and conversational AI development.
- No deployment blocking in CI/CD. Arize integrates with GitHub Actions for running experiments, but doesn't block deployments when evaluation metrics degrade. Teams manually review results and decide whether to merge code.
- Evaluation and tracing live in separate workflows. Dataset management exists separately from the tracing interface. Correlating evaluation results to specific production traces requires manual work.
- Limited pre-production simulation. The platform focuses on production monitoring. Testing prompts against synthetic datasets before deployment requires external tooling or custom scripts.
Teams shipping LLM applications need platforms that integrate evaluation, experimentation, and observability into a single system, not separate tools bolted onto ML monitoring infrastructure.
Top 5 Arize alternatives (2026)
1. Braintrust: End-to-end LLM observability and evaluation platform
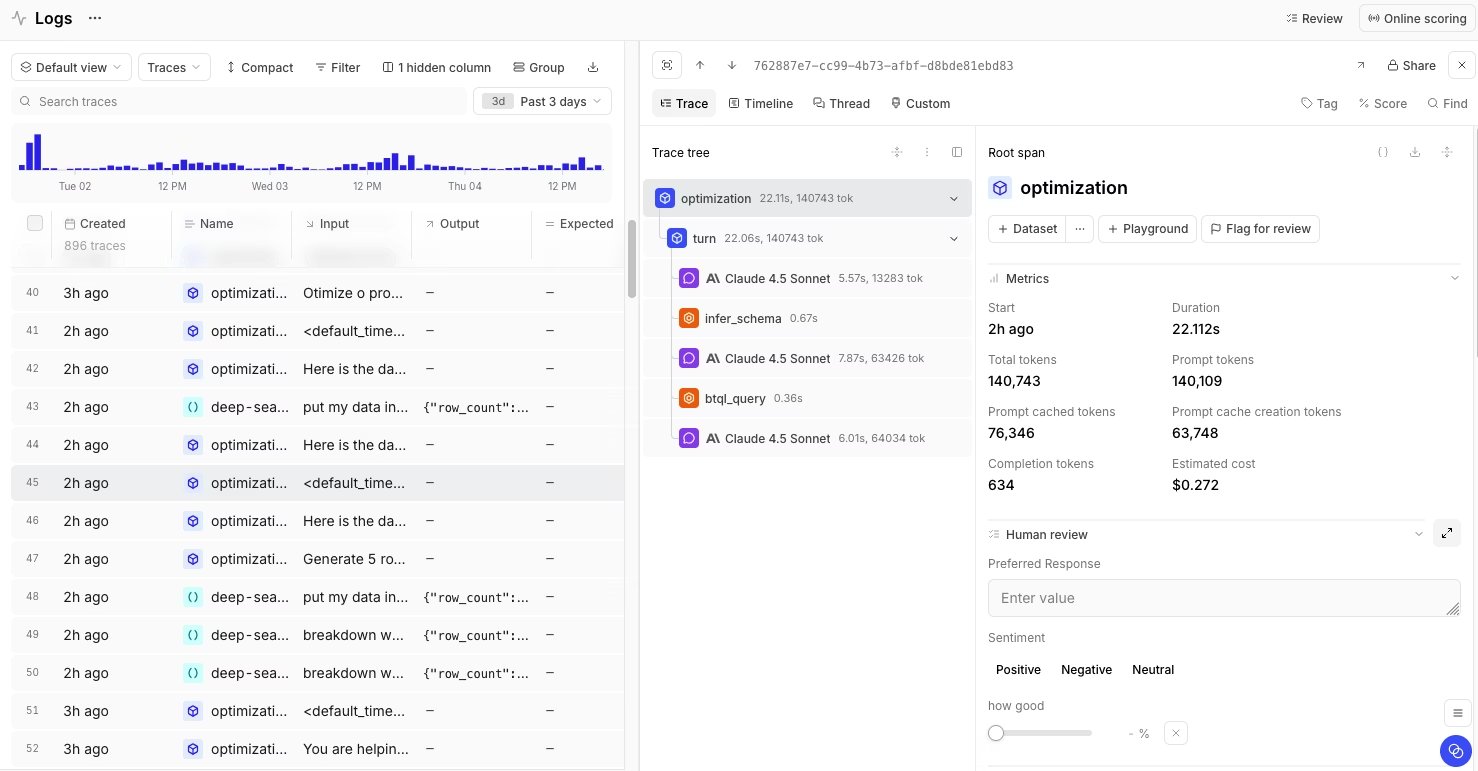
Braintrust takes an evaluation-first approach to LLM development. Automated evals run in CI/CD pipelines and block deployments when quality drops, catching regressions before users see them. Unlike LLM observability tools that surface issues after release, Braintrust prevents bad prompts from shipping with proactive measurements.
Braintrust consolidates experimentation, evaluation, and observability into a single system. Teams use Braintrust instead of juggling multiple tools. Traces, evals, and decisions stay in one place, with engineers and product managers reviewing outputs together and choosing what ships. Topics classification and the Loop agent run in the background rather than waiting for you to query a dashboard, so the traces worth acting on surface on their own and you spend model calls where they matter instead of scoring everything.
Pros
Evaluation framework
- Write custom scorers in Python or TypeScript using Autoevals for any quality metric
- Run evals locally, in the web interface, CI/CD pipelines, or on scheduled jobs
- Automatic hallucination detection, factuality checks, and custom business logic
- AI-powered Loop agent automatically generates custom scorers tailored to your use case
- Evals with LLM as a judge
- 10,000 free eval runs monthly on free tier
Automatic tracing and logging
- SDK integration captures nested LLM calls without manual instrumentation
- AI gateway mode logs all OpenAI/Anthropic/Cohere calls with zero code changes
- Trace visualization shows full context: retrieval results, reranking scores, and final generation
- Production traces can be added directly to eval datasets
Prompt and dataset management
- Version control for prompts with full history and rollback
- Interactive playground for collaboratively testing prompts
- Dataset import from CSV, JSON, or production logs
- Collaborative annotation and labeling workflows
CI/CD native integration
- GitHub Actions and GitLab CI integration out of the box
- Eval results posted as PR comments with pass/fail status
- Automatic regression detection with deployment blocking
Deployment flexibility
- Cloud-hosted with SOC 2 compliance
- Self-hosted deployment for data residency requirements (Enterprise plan)
- API access for custom integrations
- Multi-provider support (OpenAI, Anthropic, Cohere, Azure OpenAI, custom models)
Cons
- Self-hosting requires an Enterprise plan
- Custom scorer development needs coding skills in Python or TypeScript
Best for
Companies building production LLM apps that care about accuracy, quality, and safe releases.
Pricing
Free tier includes 1 GB of processed data per month, unlimited users, and 10,000 evaluation runs. Sufficient for most early-stage teams and small production applications. Pro plan starts at $249/month, with custom enterprise plans available. See pricing details →
Why teams choose Braintrust over Arize
| Feature | Braintrust | Arize | Winner |
|---|---|---|---|
| LLM evaluation framework | ✅ Eval-first platform that gates releases | ✅ Observability-first platform with evals | Braintrust |
| Prompt versioning | ✅ Full version control with A/B testing | ✅ Has Prompt Hub with versioning | Braintrust |
| Trace visualization | ✅ Built for nested agent calls and RAG | ✅ Built on an ML monitoring foundation | Braintrust |
| Dataset management | ✅ Integrated with eval workflow and versioning | ❌ Available but separate workflow from tracing | Braintrust |
| Pre-production testing | ✅ Comprehensive experiment comparison | ❌ Limited experiment framework available | Braintrust |
| Deployment model | ✅ Cloud and on-prem or self-hosted | ✅ Cloud and on-prem or self-hosted | Tie |
| CI/CD integration | ✅ Native GitHub/GitLab integration with deployment blocking | GitHub Actions integration for experiments, no automatic deployment blocking | Braintrust |
| Free tier | ✅ 1 GB of processed data per month with unlimited users | ✅ 25K spans per month for a single user only | Braintrust |
Braintrust's combined observability and evaluation framework catches regressions before they hit production. Start with Braintrust's free tier →
2. Langfuse: Open-source LLM observability platform
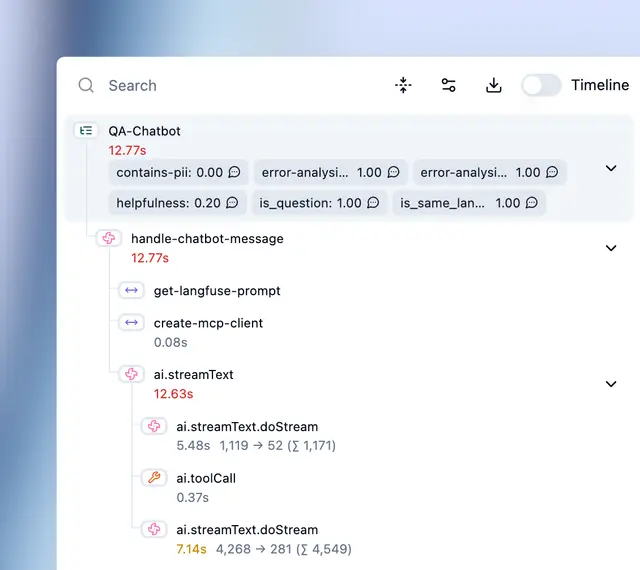
Langfuse offers an open-source observability platform offering trace logging, prompt management, and basic analytics in addition to cloud software. The open source and self-hosting option may appeal to teams with strict data policies, but you maintain infrastructure yourself.
Pros
- Self-hosted deployments
- Open source
- Manual annotation system for marking problematic outputs
- Session grouping for multi-turn conversation debugging
- Basic cost tracking across providers
Cons
- Logs traces but provides no built-in eval runners or scorers
- No CI/CD integration for automated testing or quality gates
- Basic trace viewing without experiment comparison, A/B testing, or statistical analysis
- Self-hosting requires dedicated DevOps resources for setup, maintenance, scaling, and upgrades
- Interface slows down noticeably with high trace volume, especially when viewing complex multi-agent traces
Pricing
Free for open-source self-hosting. Paid plan starts at $29/month. Custom enterprise pricing.
Best for
Teams requiring open-source self-hosted deployment with full data control who have DevOps resources to build custom evaluation pipelines from scratch.
Read our guide on Langfuse vs. Braintrust.
3. Fiddler AI: Enterprise ML and LLM monitoring platform
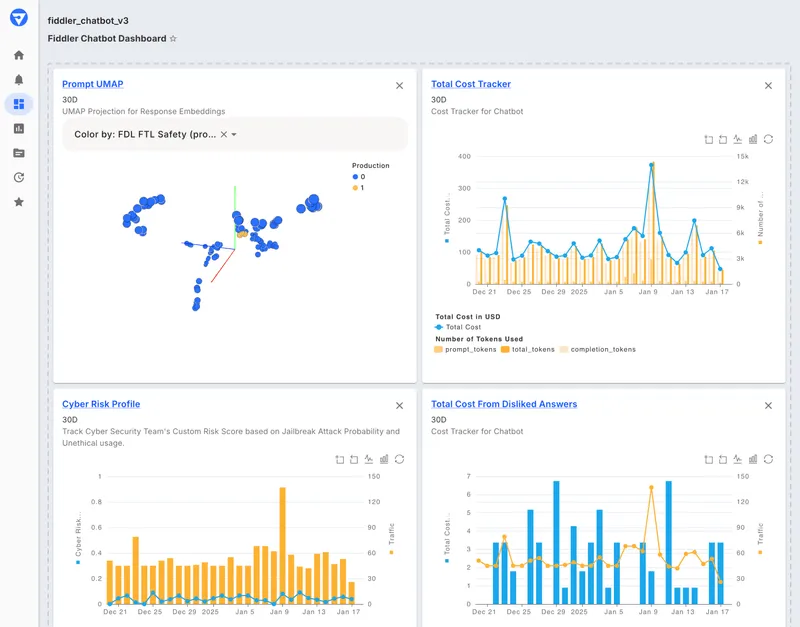
Fiddler AI is an observability platform that extends from traditional ML monitoring into LLM observability. The platform offers monitoring, explainability, and safety features for both classical ML models and generative AI applications.
Pros
- ML and LLM monitoring in one platform
- Drift detection for embeddings and model outputs
- Hallucination detection and safety guardrails
- Root cause analysis for model performance issues
- Alert configuration for quality thresholds
Cons
- The interface reflects this ML-first heritage, making LLM-specific workflows less intuitive
- No CI/CD deployment blocking
- No integrated evaluation framework
- No free tier or self-service option for teams to quickly test the platform
- No built-in version control or A/B testing framework for prompts
Pricing
Custom enterprise pricing only.
Best for
Organizations already using Fiddler for traditional ML monitoring who want unified observability across both classical and generative AI models.
4. Galileo AI: Luna-2 scoring models and 20+ prebuilt LLM evaluators out of the box
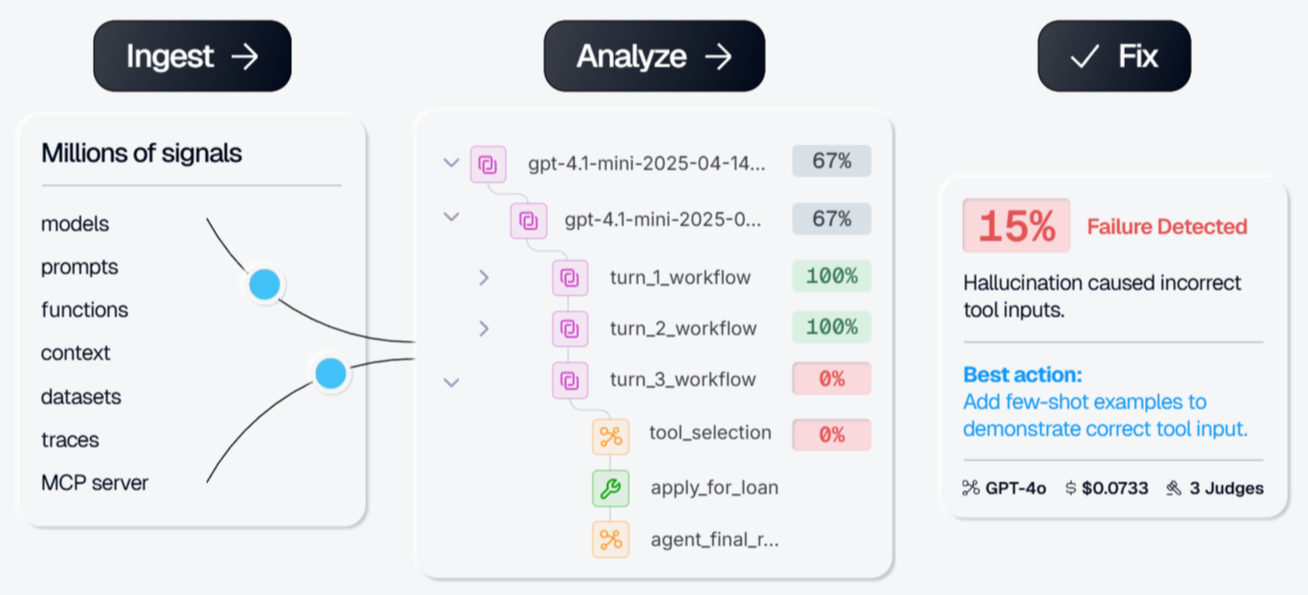
Galileo AI focuses on LLM and generative AI evaluation, where Arize started in classical ML monitoring like drift detection and model performance tracking. Scoring runs on Luna-2, a family of small language models that evaluate traces at low latency without routing every call through a frontier model. It comes with 20+ prebuilt evaluators for hallucination, context adherence, and completeness. The tradeoff is a closed stack meaning you get coverage quickly, but you cannot inspect or customize the underlying scorers. Galileo's Insights Engine focuses on surfacing failures rather than classifying every run by intent and sentiment, so teams that are running at scale and need insights beyond failures might feel limited.
Pros
- Luna-2 small language models score traces at low latency, without frontier-model calls on every trace
- 20+ prebuilt evaluators cover hallucination, context adherence, and completeness out of the box
- Inline runtime guardrails block problematic outputs before they reach users
- Galileo Insights surfaces pattern detection and root-cause analysis across traces
- Integrations for CrewAI, LangGraph, OpenAI Agent SDK, LlamaIndex, Strands, and OpenTelemetry
Cons
- Luna-2 and the prebuilt evaluators are vendor-maintained, so teams cannot inspect or modify the scoring logic
- Runtime guardrails are gated to the Enterprise tier, inaccessible on Free and Pro plans
- No native CI/CD deployment blocking, so evaluation results don't gate releases without custom work
- Free tier caps at 5,000 traces per month
Pricing
Free tier includes 5,000 traces per month. Pro is $100/month with 50,000 traces on a usage-based model. Enterprise pricing is custom and required to unlock runtime guardrails.
Best for
Teams working mainly on LLM and generative AI evaluation who want a fast setup through prebuilt scoring and inline guardrails, and who are comfortable with a vendor-maintained scoring stack rather than building and customizing their own. Galileo's Insights Engine leans toward surfacing failures, so it fits teams whose main need is catching and diagnosing problems in production traces.
Read our guide on Galileo AI vs. Braintrust.
5. Helicone: OpenAI proxy with cost tracking
Helicone acts as an LLM proxy between your app and LLM providers. It logs requests and responses, but stops at observability. No evals, datasets, or experimentation.
Pros
- Simple proxy setup requiring only endpoint change
- Cost tracking with per-user spending breakdowns
- Request count and latency monitoring
- Low latency overhead for OpenAI calls
- Dashboard showing usage patterns
Cons
- No eval framework, no scorers, no automated testing
- Can't build test suites, version datasets, or create evaluation workflows
- No prompt comparison, A/B testing, or quality analysis beyond basic dashboards
- No self-hosting; cloud-only deployment
- Basic logging without deep trace visualization, nested call analysis, or debugging tools
Pricing
Free tier (10,000 requests/month). Paid plan at $79/month.
Best for
Teams using only OpenAI models who need basic proxy logging and cost tracking without evaluation capabilities or multi-provider support.
Arize alternative feature comparison
| Feature | Braintrust | Langfuse | Fiddler AI | Galileo AI | Helicone |
|---|---|---|---|---|---|
| Distributed tracing | ✅ | ✅ | ✅ | ✅ | ✅ |
| Evaluation framework | ✅ Native | ✅ Experiments, LLM-as-Judge | ✅ | ✅ | ❌ |
| CI/CD integration | ✅ | ✅ Documented guides | ❌ | Partial | ❌ |
| Deployment blocking | ✅ | ❌ | ❌ | ❌ | ❌ |
| Prompt versioning | ✅ | ✅ | ❌ | ✅ | ❌ |
| Dataset management | ✅ | ✅ | ✅ | ✅ | ❌ |
| Self-hosting | ✅ | ✅ | ✅ | ✅ | ❌ |
| Proxy mode | ✅ | ❌ | ❌ | ❌ | ✅ |
| Multi-provider support | ✅ | ✅ | ✅ | ✅ | ❌ OpenAI only |
| Experiment comparison | ✅ | ✅ | ✅ | ✅ | ❌ |
| Custom scorers | ✅ | ✅ | ✅ | ✅ | ❌ |
| A/B testing | ✅ | ❌ | ❌ | Partial | ❌ |
| Cost tracking | ✅ | ✅ | ✅ | ✅ | ✅ |
| ML model monitoring | ❌ | ❌ | ✅ | ❌ | ❌ |
| Free tier | 1 GB data, 10K evals | 50K units | None | 5K traces | 10K requests |
Choosing the right Arize alternative
Choose Braintrust if: You need CI/CD deployment blocking, end-to-end evaluation workflows, cross-functional collaboration, flexible insights with Topics, or complex multi-agent tracing.
Choose Langfuse if: Open-source self-hosting is mandatory and you have resources to build custom eval pipelines.
Choose Fiddler AI if: You already use Fiddler for ML monitoring and need unified observability across traditional and generative AI models.
Choose Galileo AI if: You need prebuilt evaluators and inline runtime guardrails, operate in a regulated or high-risk environment at Enterprise scale, and do not need insights beyond surfacing failures.
Choose Helicone if: You only use OpenAI and need basic proxy logging without evaluation capabilities.
Final recommendation
Braintrust covers the entire LLM development lifecycle, including prompt experimentation, automated CI/CD evaluation, statistical comparison, deployment blocking, and production observability. The free tier includes 1 GB of processed data and 10K eval runs to catch regressions before customers see them.
Companies like Notion, Zapier, Stripe, and Vercel use Braintrust in production. Notion reported going from fixing 3 issues per day to 30 after adopting the platform.
Get started free or schedule a demo to see how Braintrust handles evaluation and observability for production LLM applications.
Frequently asked questions
What is the best alternative to Arize for LLM observability?
Braintrust offers the most complete Arize alternative with CI/CD-native evaluation, automatic deployment blocking, and integrated observability. Unlike Arize's ML-first architecture, where LLM features were added later, Braintrust was built specifically for generative AI workflows from day one. The platform combines prompt experimentation, automated testing, and production tracing in one system, eliminating the need to stitch together multiple tools.
Does Arize have a free tier for LLM tracing?
Arize's hosted free tier (Arize AX) includes 25K trace spans per month for a single user, and Arize Phoenix is free and open source if you self-host. Braintrust's free tier includes 1 GB of processed data and 10K evaluation runs monthly for unlimited users. Braintrust's free tier also includes CI/CD integration and deployment blocking features that Arize doesn't offer, even in paid plans.
Do I need separate tools for LLM tracing and evaluation?
Not with modern platforms. Braintrust consolidates tracing, evaluation, prompt management, and dataset versioning in one system. Evaluation results automatically link to specific traces and datasets.
Which LLM observability platform works with multiple AI providers?
Braintrust, Langfuse, Galileo AI, and Fiddler AI support multiple providers, including OpenAI, Anthropic, Cohere, and Azure OpenAI. Helicone only supports OpenAI. Braintrust's AI gateway works with all major providers without code changes. Galileo AI isn't framework-specific, but it has no equivalent gateway and requires SDK instrumentation for each service you want to monitor.
How does Braintrust compare to Arize for LLM tracing?
Braintrust's free tier includes 1 GB of processed data and unlimited users instead of one, plus evaluation features that Phoenix lacks. Braintrust provides CI/CD deployment blocking, prompt versioning with A/B testing, and integrated dataset management. Phoenix focuses on tracing without evaluation automation.